-
데이터 사이언스: Seaborn 상관관계(Correlation coefficient ), 탐색적 데이터분석(EDA), 클러스터 분석(Cluster analysis) 공부하기!데이터 사이언스 2020. 7. 31. 01:50
< 상관관계 >
상관관계란 무엇일까요?
두 대상이 서로 관련성이 있다고 추즉되는 관계를 말합니다. 쉽게 말해 얼마나 관련성이 있냐! 그 말입니다.

출처: 네이버 지식백과 한 예로 자존감과 성적의 관계를 생각해보면
대학생의 자존감과 성적 간의 상관관계를 밝히기 위해 대학생 500명을 대상으로 성적을 조사하고 설문지를 통해 자존감
수준을 측정했다고 합시다 그다음 자존감과 성적 간의 상관을 계산했을 때 두 가지 유형이 나올 수 있는데
상관계수가 양일때와 음일때입니다.
상관계수는 피어슨 상관계수를 사용하며 -1부터 1까지의 값을 갖습니다.
가령 자존감과 성적 간의 상관계수가 +0.73이라면, 자존감과 성적이 서로 관련되는 정도가 0.73만큼 정적(+)으로 강하게
관련됨을 의미하고 음이라면 성적과 자존감이 관련이 있지만, 부적(-)입니다.

네이버 지식백과 즉, 자존감이 높은 학생일수록 성적도 상당히 높을 가능성이 있습니다. 물론 상관계수는 인과관계가 아니므로 성적이 높
은 학생일수록 자존감도 매우 높을 가능성이 있다고 해석할 수 있습니다.
seaborn 라이브러리를 이용해서 상관관계를 알 수 있는데요
다음과 같은 수학점수, 읽기점수, 쓰기점수가 있는 데이터가 있을 때
import pandas as pd import seaborn as sns exam_df = pd.read_csv("Downloads/exam.csv") df = exam_df.iloc[:, 5:8] df
상관계수를 알아보면 다음과 같습니다.
df.corr()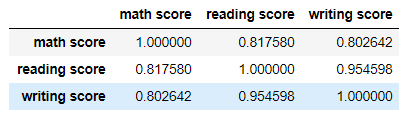
상관계수가 1에 가깝다면 정적으로 연관성이 아주 크다는 뜻이고
-1 에 가깝다면 부적으로 연관성이 크다는 뜻입니다.
읽기 점수와 쓰기점수의 상관계수는 약 0.95인데
이는 읽기점수가 높을수록 쓰기 점수가 높을 확률이 아주 크다는 뜻입니다.
상관계수는 seaborn의 heatmap 함수를 이용하면 상관계수를 시각화할 수 있습니다.
sns.heatmap(df.corr())
색이 밝을수록 양의 상관관계
색이 어두울수록 음의 상관관계를 나타냅니다.
sns.heatmap(df.corr(), annot = True)
만약 상관계수 수치도 정확하게 알고 싶다면
annot = True를 추가합니다.
< 탐색적 데이터 분석 EDA(Exploratory data analysis) >
탐색적 데이터 분석은 주어진 데이터를 다양한 관점에서 살펴보고 탐색하면서 인사이트를 찾는 과정입니다.
데이터의 어떤 분포와 어떤 연관성을 찾고 시각화와 통계적 개념을 통해서 여러가지를 의미를 도출합니다.
예를들어 성별에 따른 관심분야, 흥미 이런것들을 생각할 수 있습니다.
그래서 EDA는 도출해내기 나름이라 정해진 룰이나 공식은 없습니다.
설문조사 내용을 토대로 데이터 분석을 해봅시다.
survey_df = pd.read_csv(Downloads/young_survey.csv) survey_df2 = survey_df.iloc[:, 140:] survey_df2
sns.violinplot(data = survey_df, 2 y = "Age")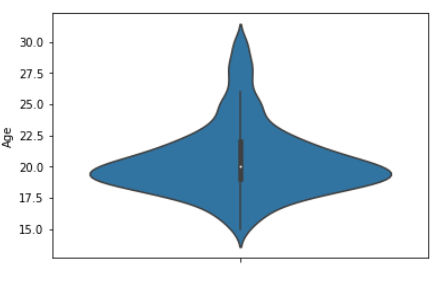
설문대상자들은 대체로 20대가 가장 많고
젊은 사람들 위주로 설문조사를 진행했네요
sns.violinplot(data = survey_df2, x = "Handness", y = "Age")
오른손잡이 데이터가 전에 본 데이터와 더 비슷하게 생겼군요.
오른손잡이의 비율이 왼손잡이 보다 좀 더 많은 것 같습니다.
sns.violinplot(data = survey_df2, x = "Handness", y = "Age", hue = "Gender")
성별에 따라 나누었습니다.
대체로 오른손 잡이 설문대상자들의 성별에 따른 평균 나이는
남자가 더 많은 것 같습니다.
하지만 왼손잡이는 비슷해보입니다.
sns.catplot(data = survey_df2, x= "Handness", y = "Height", kind = "swarm", hue = "Gender")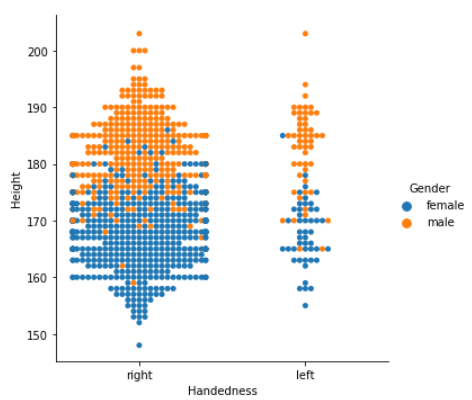
오른손잡이가 왼손잡이보다 많습니다.
대체로 남성들이 여성들보다 키가 큽니다.
sns.jointplot(data = survey_df2, x = "Height", y = "Weight")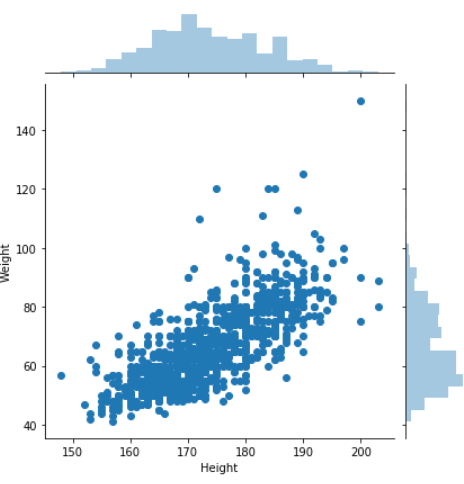
키와 몸무게에 대한 jointplot()입니다.
산점도와 히스토그램을 알 수 있네요
산점도를 보면 둘의 상관관계가 대체로 정적(+)음을 알 수 있고
히스토그램을 보면
키가 약 170cm, 몸무게 약 60kg인 사람들의 비율이 가장 많은 것을 알 수 있네요
설문대상자들의 음악 선호도를 조사한 자료입니다.
survey_df = pd.read_csv("Downloads/young_suervey.csv") music_df = survey_df.iloc[:, :19] music_df.head()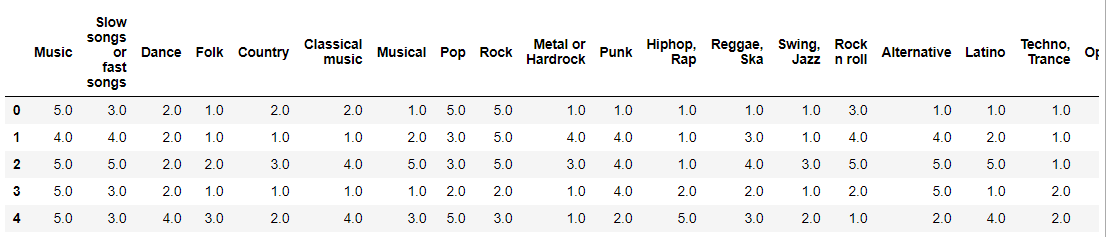
히트맵을 이용해서 Pop음악을 좋아하는 사람들은 대체로 어떤 음악을 좋아하고 싫어하는지 알아봅시다.
sns.heatmap(music_df.corr())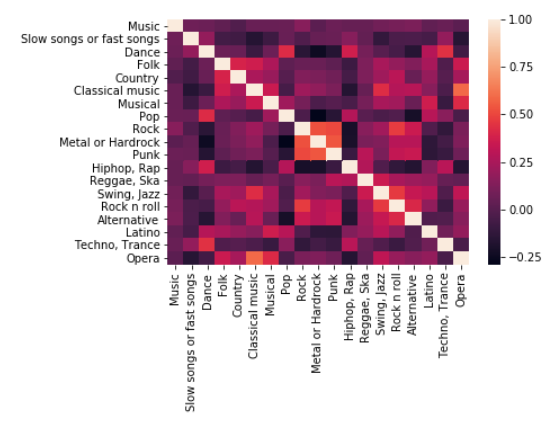
Pop을 좋아하는 사람들은 대체로 Dance음악을 좋아할 확률이 높고
Metal or Hardrock을 싫어할 확률이 높네요
이번에는 아침에 일어나는 사람들이 어떤 음악을 좋아하는지 알아봅시다
일찍 일어나는 사람일수록 1점에 가깝고
늦게 일어나는 사람일수록 5점에 가깝습니다.
music_df["Getting up"] = survey_df["Getting up"] music_df.corr()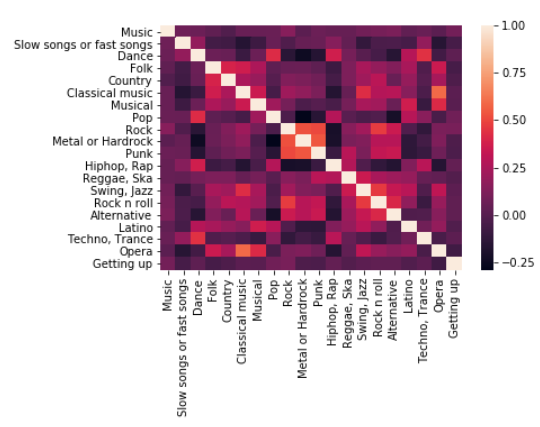
music_df.corr["Getting up"].sort_values()Opera -0.071819 Slow songs or fast songs -0.052613 Folk -0.049612 Punk -0.029189 Metal or Hardrock -0.026769 Country -0.025315 Latino -0.015060 Reggae, Ska -0.008434 Musical 0.011869 Classical music 0.014285 Swing, Jazz 0.019556 Techno, Trance 0.019863 Dance 0.027249 Alternative 0.027540 Rock n roll 0.028889 Hiphop, Rap 0.038980 Pop 0.079101 Music 0.090009 Rock 0.105245 Getting up 1.000000 Name: Getting up, dtype: float64상관계수가 가장 작은 값을 갖는 음악은 Opera네요
아침에 일찍일어나는 사람일수록 Opera를 좋아할 확률이 크네요.
반면 Rock을 싫어할 확률이 큽니다.
< 클러스터 분석(Cluster analysis) >
어떠한 데이터들의 유사성을 기준으로 여러개의 집합(클러스터)로
분류하고 유형화하는 통계 기법입니다.
한 예로, 학창시절 이과, 문과, 예체능으로 나누듯이 어떠한 기준을 가지고
그룹을 나누는것을 의미합니다.
설문대상자들의 흥미를 기반으로 한 데이터입니다.
같은 흥미를 가진 사람들끼리 그룹을 나누어봅시다.
interest_df = survey_df.loc[:, "History": "Pets"].corr() sns.clustermap(interest_df)
클러스터맵은 히트맵과 유사하게 생겼지만 대진표가 있습니다.
이 대진표는 가장 연관성이 높은 항목들순으로 연결되어 있습니다.
예를들어, Medicine과 Biology가 연결되어 있는데
이는 Medicine을 좋아하는 사람일수록 Biology를 좋아할 확률이 크다는 의미입니다.
반면, Politic과 PC는 멀리 떨어져 있는데 이는 두 흥미간의 연관성이 떨어진다는 것을 의미하죠
이렇게 어떤 기준을 통해서 쉽게 그룹을 만들고 유형화할 수 있는게 클러스터 분석입니다.
반응형'데이터 사이언스' 카테고리의 다른 글