-
데이터 사이언스: Pandas 로 큰 데이터를 다루기(info, describe, unique, value_counts, sort_values), 데이터합치기(merge)데이터 사이언스 2020. 7. 26. 23:31
< 큰데이터 다루기 >
Pandas로 큰 데이터를 다루어 봅시다!
우선 데이터를 하나 받아옵시다.
import pandas as pd df = pd.read_csv("Downloads/laptops.csv") df
데이터 크기가 너무 클 경우에는 ...으로 표현됩니다.
그래서 데이터를 보고 싶은 부분만 가져오기 위해 head를 이용합시다
df.head(N)를 이용하면 첫번째 행부터 N번 째 행까지 가져옵니다.
default 값은 5라서 아무값도 입력하지 않으면 5줄의 행만 가져옵니다.
df.head()
tail()은 head()와 반대로 뒤에서부터 가져옵니다.
head와 마찬가지로 default 값으로 5를 갖습니다.
df.tail()
데이터 프레임의 정보를 가져옵니다.
df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 167 entries, 0 to 166 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 brand 167 non-null object 1 model 167 non-null object 2 ram 167 non-null int64 3 hd_type 167 non-null object 4 hd_size 167 non-null int64 5 screen_size 167 non-null float64 6 price 167 non-null int64 7 processor_brand 167 non-null object 8 processor_model 167 non-null object 9 clock_speed 166 non-null float64 10 graphic_card_brand 163 non-null object 11 graphic_card_size 81 non-null float64 12 os 167 non-null object 13 weight 160 non-null float64 14 comments 55 non-null object dtypes: float64(4), int64(3), object(8) memory usage: 19.7+ KB각 칼러들의 갯수, 평균값, 표준편차, 최소, 최대를 가져옵니다.
df.describe()
원하는 칼럼으로 값을 정렬합니다.
가격을 기준으로 정렬하면 다음과 같습니다. 아무것도 설정해주지 않으면 오름차순으로 정렬됩니다.
df.sort_values(by = "price")
만약 내림차순으로 정렬하고 싶다면, ascending = False로 설정합니다.
df.sort_values(by = "price", ascending = False)
"brand"에 어떤 요소가 있는지 확인해봅시다.
df["brand"].unique()array(['Apple', 'Alienware', 'Acer', 'Microsoft', 'HP', 'Dell', 'Lenovo', 'Asus'], dtype=object)unique에서 확인한 요소들이 몇개씩 들어있는지 확인해 봅시다.
df["brand"].value_counts()HP 55 Acer 35 Dell 31 Lenovo 18 Asus 9 Apple 7 Alienware 6 Microsoft 6 Name: brand, dtype: int64이렇게 열 하나만 떼어내서 describe을 할 수도 있습니다.
df["brand"].describe()count 167 unique 8 top HP freq 55 Name: brand, dtype: object 큰 데이터를 좀 더 능숙하게 다루기 위해 간단한 예제하나 풀어봅시다.
1. 인구밀도(Population/Land area(in sqKm))가 10000이상인 나라를 찾아봅시다.
2. "인구밀도"란을 데이터 프레임에 추가해봅시당.
3. 데이터 프레임에서 4개 있는 나라를 찾아봅시닥.
다음과 같은 데이터프레임이 있습니다.
import pandas as pd df = pd.read_cdv("Downloads/world_cities.csv") df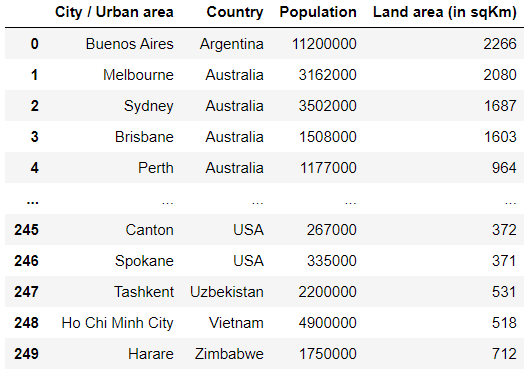
1. 인구밀도가 10000이상인 나라
x = df["Populatoin"] / df["Land area(in sqKm)"] > 10000 df[x]
2. "인구밀도"란 추가
df["인구밀도"] = df["Population"]/df["Land area (in sqKm)"] df.sort_values(by = "인구밀도", ascending = False)
3. 4개인 나라 찾기
x = df["Country"].value_counts() == 4 df["Country"].value_counts()[x]Italy 4 Name: Country, dtype: int64
< 데이터 합치기 >
다음과 같은 두 개의 데이터를 합쳐봅시다. 데이터를 합칠때 4개의 기준이 있는데
1. Inner join
두 데이터(left data, right data)가 가지고 있는 column data를 "product" 라고 할 때
left data 에도 있고, right data에도 있는 product 값들만 출력합니다.
교집합이라고 생각하시면 됩니다.
2. Left outer join
두 데이터(left data, right data)가 가지고 있는 column data를 "product" 라고 할 때
left data 에 있고, right data에는 없는 product 값들만 출력합니다.
3. Right outer join
두 데이터(left data, right data)가 가지고 있는 column data를 "product" 라고 할 때
left data 에 없고, right data에는 있는 product 값들만 출력합니다.
4. Full outer join
두 데이터(left data, right data)가 가지고 있는 column data를 "product" 라고 할 때
left data 에 없든, right data에도 없든 모든 product 값들을 출력합니다.
합집합이라고 생각하시면 됩니다.
야채의 가격데이터와 수량 데이터가 있습니다.
import pandas as apd price_df = pd.read_csv("Downloads/vegetable_price.csv") quantity_df = pd.read_csv("Downloads/vegetable_price.csv")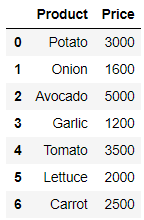
price_df 
quantity_df Inner join
pd.merge(price_df, quantity_df, on = "Product")
Left outer join
pd.merge(price_df, quantity_df, on = "Product", how = "left")
이렇게 없는 값들은 NaN으로 처리가 됩니다.
Right outer join
pd.merge(price_df, quantity_df, on = "Product", how = "right")
Full outer join
pd.merge(price_df, quantity_df, on = "Product", how = "outer")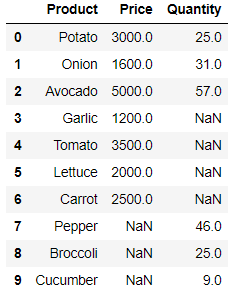 반응형
반응형'데이터 사이언스' 카테고리의 다른 글
데이터 사이언스: Seaborn 데이터 시각화 공부하기!(kde, violin, cat, distplot... ) (0) 2020.07.28 데이터 사이언스: Pandas plot의 종류와 특성 공부하기!(박스플롯, 산점도, 선, 막대, 원, 히스토그램) (0) 2020.07.27 데이터 사이언스: Pandas 잘못된 데이터 고치기 (rename, set_index) (0) 2020.07.25 데이터 사이언스: Pandas 데이터(csv파일) 받아오기, 인덱싱(Indexing), 데이터 변형 공부하기! (0) 2020.07.24 데이터 사이언스: Pandas 시리즈(Series)와 데이터 프레임(Data Frame) 공부하기! (0) 2020.07.21