-
데이터 사이언스: Pandas 데이터(csv파일) 받아오기, 인덱싱(Indexing), 데이터 변형 공부하기!데이터 사이언스 2020. 7. 24. 22:50
1. 판다스(Pandas)로 데이터 받아오기
판다스 내부 메소드 read_csv()로 .csv 파일을 가져온다.
import pandas as pd df_iphone = pd.read_csv("Downloads/iphone.csv", index_col = 0) # index_col = 0 첫번째 칼럼을 인덱스로 한다는 의미 df_iphone
2.1 판다스(Pandas) loc 인덱싱
df.loc["a", "b"] = 행이 "a"이고, 열이 "b"인 값을 가져온다.
(loc는 location을 의미)
df_iphone.loc["iPhone 8"] # "iPhone8" 행을 가져온다출시일 2017-09-22 디스플레이 4.7 메모리 2GB 출시 버전 iOS 11.0 Face ID No Name: iPhone 8, dtype: objectdf_iphone.loc["iPhone 8", "출시일"] # "iPhone 8"행, "출시일" 열에 해당하는 값을 가져온다'2017-09-22'df_iphone.loc[:,'메모리'] # 모든행, '메모리'열 즉, "메모리" 열의 값들을 가져온다.iPhone 7 2GB iPhone 7 Plus 3GB iPhone 8 2GB iPhone 8 Plus 3GB iPhone X 3GB iPhone XS 4GB iPhone XS Max 4GB Name: 메모리, dtype: objectdf_iphone[["출시일", "디스플레이"]] # "출시일", "디스플레이" 열 값들을 가져온다. df_iphone.loc[:,["출시일", "디스플레이"]] # "출시일", "디스플레이" 열 값들을 가져온다.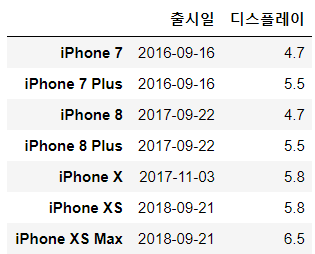
두 결과 값이 같다.
※ 단, 행에 대해서는 df_iphone[["iPhone X", "iPhone XS"]] 이런것들이 불가능하다.
df_iphone.loc[["iPhone X", "iPhone XS"]] ☜ 얘는 가능, 헷갈린다. 그냥 loc를 쓰자.
불린(Boolean) 값을 이용한 인덱싱
condition = df_iphone.loc[:,"디스플레이"] > 5 # 디스플레이 값이 5보다 큰 값을 기준으로 True # True인 값들을 리턴한다. df_iphone.loc[condition]<condition 값>
iPhone 7 False iPhone 7 Plus True iPhone 8 False iPhone 8 Plus True iPhone X True iPhone XS True iPhone XS Max True Name: 디스플레이, dtype: bool<df_iphone.loc[condition] 값>

2.2 판다스(Pandas) iloc 인덱싱
인덱스가 i인 행, 인덱스가 j인 열의 값을 가져온다.
(iloc는 index location이라는 뜻!)
df_iphone.iloc[[1,3], [2, 3]]
인덱스 값 기준 (1, 2), (1, 3), (3, 2), (3, 3)을 모아놓은 데이터프레임
3.1 데이터 변형하기
df_iphone.loc["iPhone 8"] = "x" # "iPhone 8" 행의 모든 값을 x로 df_iphone
df_iphone.loc[df_iphone["Face ID"] == "Yes", "디스플레이"] = "x" # df_iphone["Face ID"] == "Yes"을 만족하는 행, "디스플레이" 열 값에 x를 넣는다. df_iphone
3.2 열 추가하기
df_iphone["제조사"] = "Apple" # 존재하지 않는 열 이름과 원하는 값 df_iphone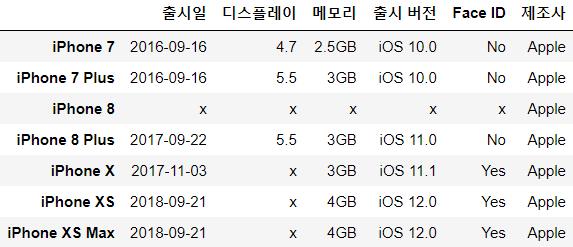
3.3 행 추가하기
df_iphone.loc["iPhone XR"] = ["2018-09-21","o",'8GB',"iOS 12.0",'Yes','Apple'] # 존재하지 않는 행과 원하는 값 df_iphone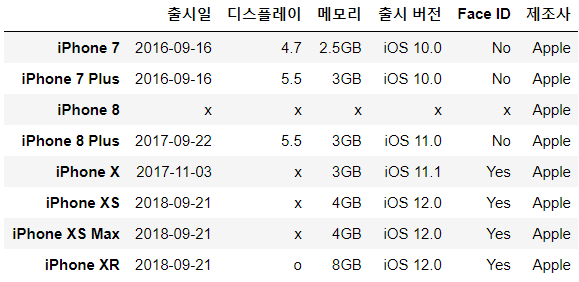
3.3 열 제거하기
df.drop(지우고자 하는 열 이름, axis = "columns", inplace = True)
inplace = False 일 경우, 원래 데이터가 바뀌지 않는다.
df_iphone.drop("제조사",axis = "columns", inplace = True)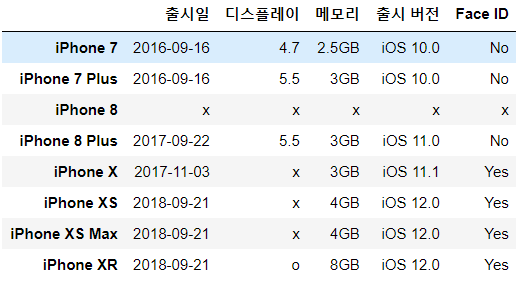
3.4 행 제거하기
df.drop(지우고자 하는 행 이름, axis = "index", inplace = True)
inplace = False 일 경우, 원래 데이터가 바뀌지 않는다.
df_iphone.drop("iPhone XR", axis = "index", inplace = True) 반응형
반응형'데이터 사이언스' 카테고리의 다른 글
데이터 사이언스: Pandas 로 큰 데이터를 다루기(info, describe, unique, value_counts, sort_values), 데이터합치기(merge) (0) 2020.07.26 데이터 사이언스: Pandas 잘못된 데이터 고치기 (rename, set_index) (0) 2020.07.25 데이터 사이언스: Pandas 시리즈(Series)와 데이터 프레임(Data Frame) 공부하기! (0) 2020.07.21 데이터 사이언스: numpy 연산과 통계 값들 구하기(표준편차, 분산, 평균, 중앙값...) (0) 2020.07.18 데이터 사이언스: numpy 기본사용법과 인덱싱(Indexing) 공부하기! (0) 2020.07.18