-
머신러닝: Training Neural Networks 공부하기2 (Optimization, Learning Rate, Regularization)머신러닝 2020. 10. 20. 22:59
<최적화 (Optimization)>
우선 경사하강법(Gradient descent)는 가장 작은 loss를 갖는 W값을 찾기 위해 gradient를 이용한다.
그리고 SGD는 이를 mini batch를 이용하여 더 효율적으로 W를 찾는 방법이다.
하지만 SGD는 다음과 같은 상황들에 대해서 문제점을 지닌다.
만약 Loss 값이 급격하게 증가하거나 감소한다면 이 때는 얕은 차원이나 가파른 경사 때문에
발산하거나 진동하여 최적의 W를 찾는 과정은 느려진다.
또한 다음과 같이 경우 문제점을 갖는다.

1) local minima를 갖는 부분
우리가 원하는 W는 가장 작은 loss가질때이다.
하지만 첫번째 그래프는 global minima가 아닌 local minima에서
optimization을 멈출 가능성이 있으므로 문제가 발생한다.
2) saddle point에 걸렸을 때
두번째 그래프 또한 마찬가지로 중간의 saddle point에 걸렸을 때
optimization이 끝나므로 문제가 생길 수 있다.
그래서 이를 해결하기 위해 Momentum이라는 개념을 사용한다.
기존의 gradient에 velocity를 추가하여 weight를 업데이트하는 것이다.


하지만 실제로 SGD + Momentum 또한 문제가 있지만
이번 포스팅에서 다루지 않겠다.
이 문제를 해결한 방식으로 Nesterov Momentum이 있다.

사실상 위의 방식 Momentum update와 같은 방식이다.
momentum을 추가하여 문제점을 개선하였다.
그리고 이러한 Gradient descent방식을 이용한 여러가지 Optimizer가 있다.
1) AdaGrad

grad_squared에다가 dx를 제곱한것을 Momentum으로 잡는다.
grad_squared가 커짐에 따라 dx가 덜 나가고
grad_squared가 작아짐에 따라 dx가 더 나가게 된다.
하지만 grad_squared의 누적이 지속적으로 커지게 되면 나중엔 step size가 0을 향한다.
이를 피하기 위해 만든것이 RMSProp이다.
2)RMSProp

decay_rate를 추가해서 step_size가 0이 되는 상황을 피한다.
3) Adam
optimizer로 쓰기 가장 무난하며 많이 사용된다.

1차와 2차 함수의 모멘텀을 가지고 있으며
RMSProp에 모멘텀을 추가한 형태라고 할 수 있다.
<Learning Rate>
SGD, SGD + Momentum, Adagrad, RMSProp, Adam은 learning rate를
hyperparameter로 갖는다.

Learning rate는 너무 높아도 너무 낮아도 좋지 않다.
Learning rate를 줄여가면서 적합한 값을 찾아야 한다.
Epoch에 따라서 learning rate를 줄여나감으로써
각각의 epoch에 따른 learning rate를 알아야 한다.

그래서 이를 위해 epoch에 따른 learning rate scheduler를 따로 만들어서 사용한다.
<Test Error 개선하기>
데이터를 training할때, validation을 추가하여 현재 데이터가 잘 트레이닝되고 있는지 확인한다.
validatoin은 어떻게 보면 test데이터의 예제라고 볼 수 있다.

train은 잘 되고 있지만 val의 성적은 좋지 않은 모습이다.
그렇다면 Training을 언제까지 해야할까?
다음과 같은 트레이닝 데이터가 있다.

validation이 더이상 증가하지 않을 때 쯤 training을 그만하는게 좋다.
그 이후로 계속 training 해도 좋은 결과는 얻지 못하며 낭비이다.
(그에 맞게 epochs를 줄여준다)
<Model ensembles>
여러개의 W파라미터(독립적)를 얻은 후, 같이 classification하면 성능적으로 약 2%의 이득이 있다.
이는 대표성을 못 띄기 때문에 여러개의 모듈로 classification하면 당연히 성능이 좋아질 수 밖에 없는 것이다.
모델 앙상블 만드는 것 보다 그냥 모듈하나를 대표성있게 만들면 어떨까?
모델이 대표성을 띄지 않는 이유는 overfitting되어 비슷한 값들이라고 해도 지나치기 때문이다.
이를 막기 위해 regularization을 이용한다.

1. Dropout Regularization
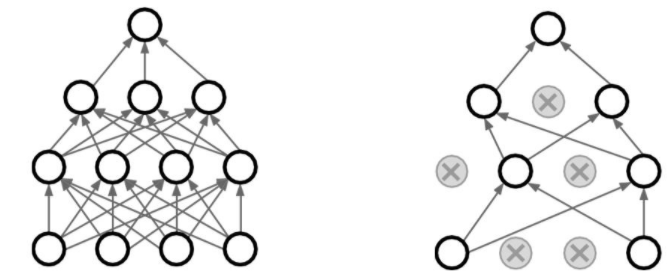
랜덤하게 몇개의 노드를 뺌으로써 regularization한다.

굳이 모든 특징을 다 갖고 있지 않아도 cat이라고 맞출 수 있다.
2. Data augmentation Regularization
이미지 자체를 transformation(대칭, 회전등)해서 regularization한다.
물론 말도 안되는 Scaling을 하면 안되며 없는 데이터를 추가시켜 나간다.
< Hyperparameter 선택하기 >
1. 초기의 loss를 이용해서 체크한다.
초기에 softmax를 이용하여 클래스의 갯수가 C개일때, loss는 log(C)가 나와야한다.
2. sample을 조금만 해서 돌려본다.
3. loss가 작아지는 learning rate를 찾는다.
4. 1 ~ 5 epochs로 돌려본다.
5. 잘 맞는 learning rate를 찾아내서 사용한다.
6. loss curve를 관찰
7. 5번으로 가서 반복

출처입니다! 반응형'머신러닝' 카테고리의 다른 글
머신러닝: 파이썬 Pytorch 사용하기! (2) 2020.11.09 머신러닝: Training Neural Networks 공부하기1(Activation function, Data preprocessing, Weight Initialization, Batch Normalization, Transfer Learning) (0) 2020.10.20 머신러닝: 역전파(back propagation) 공부하기(개념, 예제) (0) 2020.10.08 머신러닝: Image Feature를 이용한 Classification? Neural Network란? (2) 2020.10.07 머신러닝: 최적화(Optimization) 공부하기 (Gradient descent, SGD) (0) 2020.10.05