-
머신러닝: 이미지 프로세싱(Image processing)이란? 필터링(Filtering) 이란?간단한 이론정리머신러닝 2020. 9. 9. 14:06
이번 포스팅에서는 크게Template matching과Filtering에 대해 다루어 볼 것이다.
우선 이미지 프로세싱(Image Processing)이란 무엇일까?
원래의 이미지를 프로그래밍을 이용해서 내가 원하는 정보를 얻거나
이미지를 내가 원하는 방식으로 가공하는 것을 말한다.
먼저 이미지 프로세싱에 대해 알아보기 위해서 이미지는 어떻게 구성되어 있는지 알아보면
이미지란?
- 밝기 값을 표현하는 화소(pixel)들의 집합
그렇다면 화소의 특성은?
- 화소의 channel 수
회색의 경우, 채널 한개를 갖지만 일반적으로 R, G, B 3개를 갖는다
- 화소의 depth
8비트, 12비트, 16비트가 있으며
비트수가 높아질수록 화면이 더 부드러워진다.
- 화소의 밝기 값
00000000 ~ 11111111 의 값을 갖으며
낮을수록 밝은 색, 높을수록 어두운 색을 띤다.
그렇다면 이제 Template matching에 대해서 알아보자
탬플릿 매칭(Template matching)은 원본 이미지에서 내가 찾고자 하는 이미지를 찾는 모듈이다.
여기서 내가 찾고자하는 이미지를 템플릿 이미지라고 한다.
원본 이미지 위에서 탬플릿 이미지를 이동시켜 가면서
템플릿 이미지와 동일하거나, 가장 유사한 영역을 찾는 방법이다.
예를 들어서 이 그림에서

이와 비슷하게 생긴 자동차를 찾고 싶을때

template을 그림에서 scan하면서 가장 일치율이 높은 곳에 물체가 있다고 판단하게 하는 방법이다.
그렇다면 어떤 기준이 충족되어야 일치되었다고 할 수 있을까?
템플릿의 화소 값이 각 화소별로 일치하는지를 확인한다?
하지만 이것은 말처럼 쉽지 않다. 왜냐하면 템플릿과 이미지의 크기도 다를 뿐더러
보이는 시각도 다르기 때문이다.
그래서 오래전에는 템플릿 매칭은 아주 제한적인 영역에서만 사용했다고 한다.
예를들어 하늘에서 도로를 촬영했을 때 정해진 템플릿으로 차를 검출가능한 정도
그렇다면 이러한 한계를 어떻게 극복할까?
우선 방향이나 모양등이 크게 다르지 않은 경우 먼저 살펴보자
1. 템플릿과 원본의 크기 차이 문제
사물을 찾아내서 사물들의 크기를 템플릿의 크기로 맞춘다.
2. 밝기 차이 문제
두 물체의 밝기 값을 평균 밝기 값으로 고쳐서 비교한다.
이를 정규화(Normalization)라고 한다.
3. 조금 더 높은 수준의 정보 얻기
필터를 이용해서 더 높은 수준의 정보를 추출한다. 필터에 대한 내용은 후반부에서 하겠다.
반복적으로 더 높은 수준의 정보를 얻으면 피라미드 형태가 된다.
하지만 이와는 별도로 템플릿에 없는 것들(방향이 다르더던지, 모양이 다르다던지)은
원본에서 검출하기 힘들다.
그래서 다음과 방법들을 이용한다.
1. Huge dataset을 이용한 데이터 레이블링
많은 데이터를 이용한다.
2. Data agumentaion
Traning data에서 training data를 얻어내는 방법
쉽게 말하면 Rotating, scaling, clipping등을 이용한 Image deformation을 말한다.
하지만 말도 안되게 augmentation을 하는 경우 문제가 생길 수 있다.
예를 들어 보행자가 걸어가는 모습을 augmentation을 하지
물구나무서기 하는 장면을 너무 많이 추가해버리면 잘못된 정보가 검출될 수 있다.
3. 더 높은 수준의 정보를 얻어 처리하기
꼭지점을 이용한 정보라던지 이런것들을 이용
Image Filter
위에서 더 높은 수준의 정보를 얻기 위해 filter를 이용한다고 하였는데,
Filter란 쉽게 말해서 요즘 사진 보정어플을 생각하면 쉽다.
사진 보정어플에는 여러가지 종류의 필터기능이 있는데
이러한 필터 시스템을 통해 원본의 특징을 좀 더 구체화할 수 있고
이를 통해 더 높은 수준의 정보를 얻어낼 수 있다.
이러한 Image filter는 Linear system을 통해서 모델링된다.
Input -> Linear System -> Output
linear filter는 특정한 이미지 프로세싱을 하는 mask에 대해서
원본이미지를 컨볼루션한 것과 같다.

컨볼루션이 끝나고 나면 가장자리가 한칸씩 비게되고
이를 막기 위해 가장자리를 0으로 padding 하기도 한다.
그리고 이러한 Linear System은 크게
Low pass filter와 High pass filter로 나뉜다.
Low pass filter
low pass filter를 거치면 이미지가 부드럽게 변한다. (뿌옇게 변한다)

또한 mask의 크기가 더 커질수록 더 뿌옇게 변한다.
(3 x 3 filter를 이용한 것보다 5 x 5 filter를 이용한 경우가 더 뿌옇다)
High pass filter
edge부분을 좀 더 강조해서 보이게 한다.

흑백이 아니라 칼라 이미지에 대해서 필터링하는 경우도 있다.
이외에도 Edge Detection에 특화된 mask들이 있다.
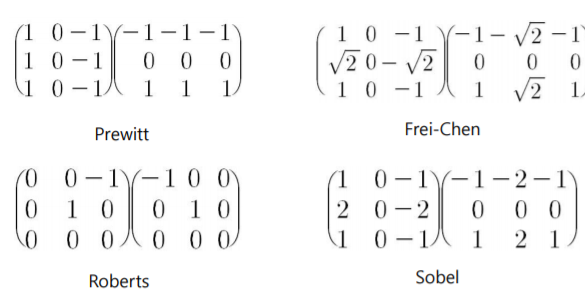
Sobel filter가 가장 많이 쓰인다고 한다.
마지막으로 Gabor filter!
가버 필터는 텍스처 정보를 얻어내는데 아주 유용하다

또한 가버필터를 다른 방법으로 활용하여 얼룩말이나 호랑이같은 특징을 가진
사물찾기에도 사용할 수 있다.
반응형'머신러닝' 카테고리의 다른 글
머신러닝: Image Feature를 이용한 Classification? Neural Network란? (2) 2020.10.07 머신러닝: 최적화(Optimization) 공부하기 (Gradient descent, SGD) (0) 2020.10.05 머신러닝: Loss function이란? (Multiclass SVM loss, Softmax Classifier ) (0) 2020.10.01 머신러닝: K-nearest neighbors란? 왜 Linear classification을 사용할까 (0) 2020.09.26 머신러닝: SVM이란? Linear classifiers, Dual form 공부하기! (0) 2020.09.14